网络爬虫又叫机器人,蜘蛛,蠕虫,网页追逐者,和流浪者,几乎和网络本身一样古老,这是一个程序,其会自动的通过网络抓取互联网上的网页,这种技术
一般可能用来检查你的站点上所有的链接是否是都是有效的。当然,更为高级的技术是把网页中的相关数据保存下来,可以成为搜索引擎。
简单的画一张图来理解下搜索引擎和爬虫的关系:
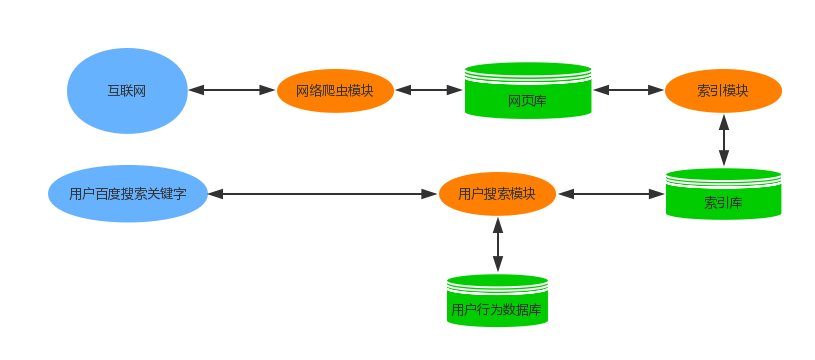
1.我们利用网络爬虫模块在互联网上不断抓取网页,对抓取回来的网页进行一定条件的解析后,把需要的内容快照存入网页数据库中。
2.索引模块对网络爬虫模块抓取回来的网页数据进行进一步分析,提取网页中的关键字,通过关键字可以映射到网页的内容,最后把关键字存入索引数据库中。
3.当用户在百度中输入关键字,用户搜索模块先去用户行为数据库中查询,是否缓存过此用户之前搜索过的对应信息,如果有,则提取出来返回给用户。
如果没有,则去索引数据库中查询与关键字匹配的内容,返回结果,并把结果缓存到用户行为数据库中。
现在我们知道,网络爬虫是搜索引擎的核心功能之一。
网络爬虫的基本结构及工作流程
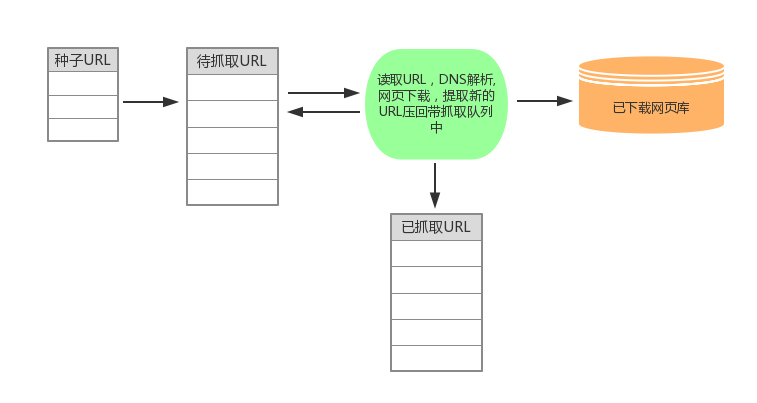
1.首先选取一部分精心挑选的种子URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页数据库中。此外,将这些URL放进 已抓取URL队列。
4.分析抓取回来网页中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓 取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。我们以下面的图为例:
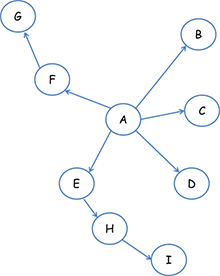
遍历的路径:A-F-G E-H-I B C D
2.宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后 再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以上面的图为例:
遍历路径:A-B-C-D-E-F G H I
3.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数量。反向链接数表示的是一个网页的内容受到其他人的推荐的程度。因此,很多时候搜索引擎的抓取系统 会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序。
在真实的网络环境中,由于广告链接、作弊链接的存在,反向链接数不能完全代表网页的重要程度。因此,搜索引擎往往考虑一些可靠的反向链接数。
4.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因此叫做大站优先策略。
其他的抓取策略就不一一介绍了。
DNS缓存
这个就不用多说了,在爬虫抓取网页时,如果相同域名的网页我们每次都需要进行DNS解析,那将是浪费掉我们大量的爬虫时间,所以我们可以在抓取过程中 缓存域名的IP,减轻不必要的DNS重复解析。
URL去重
假设要你写一个网络蜘蛛(web crawler)。由于网络间的链接错综复杂,蜘蛛在网络间爬行很可能会形成“环”。为了避免形成“环”,就需要知道蜘蛛已经
访问过那些URL。给一个URL,怎样知道蜘蛛是否已经访问过呢?URL去重方法有很多,这里选用bloom filter,这里就不做说明为什么用它了,我有一篇
详细的bloom filter说明。